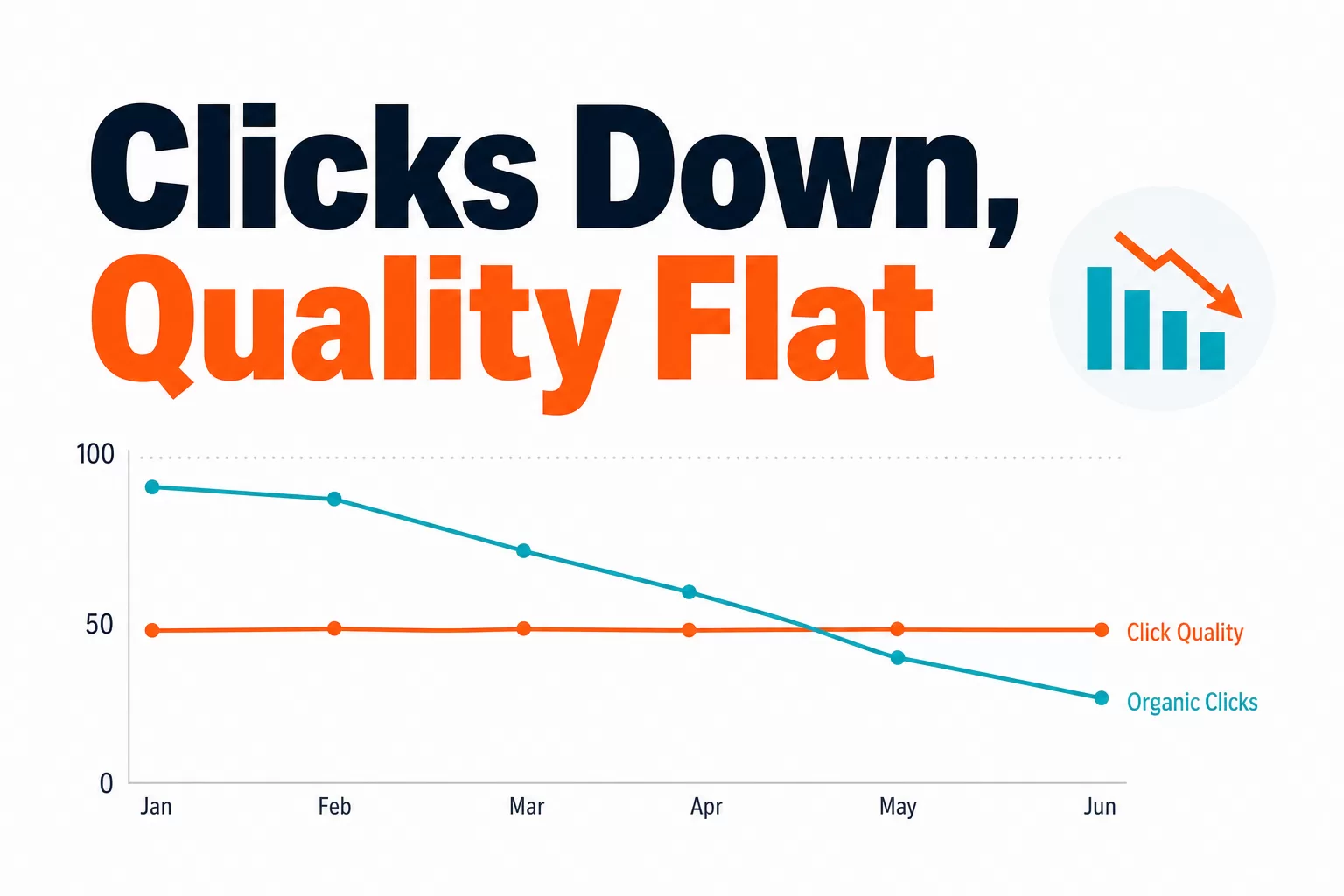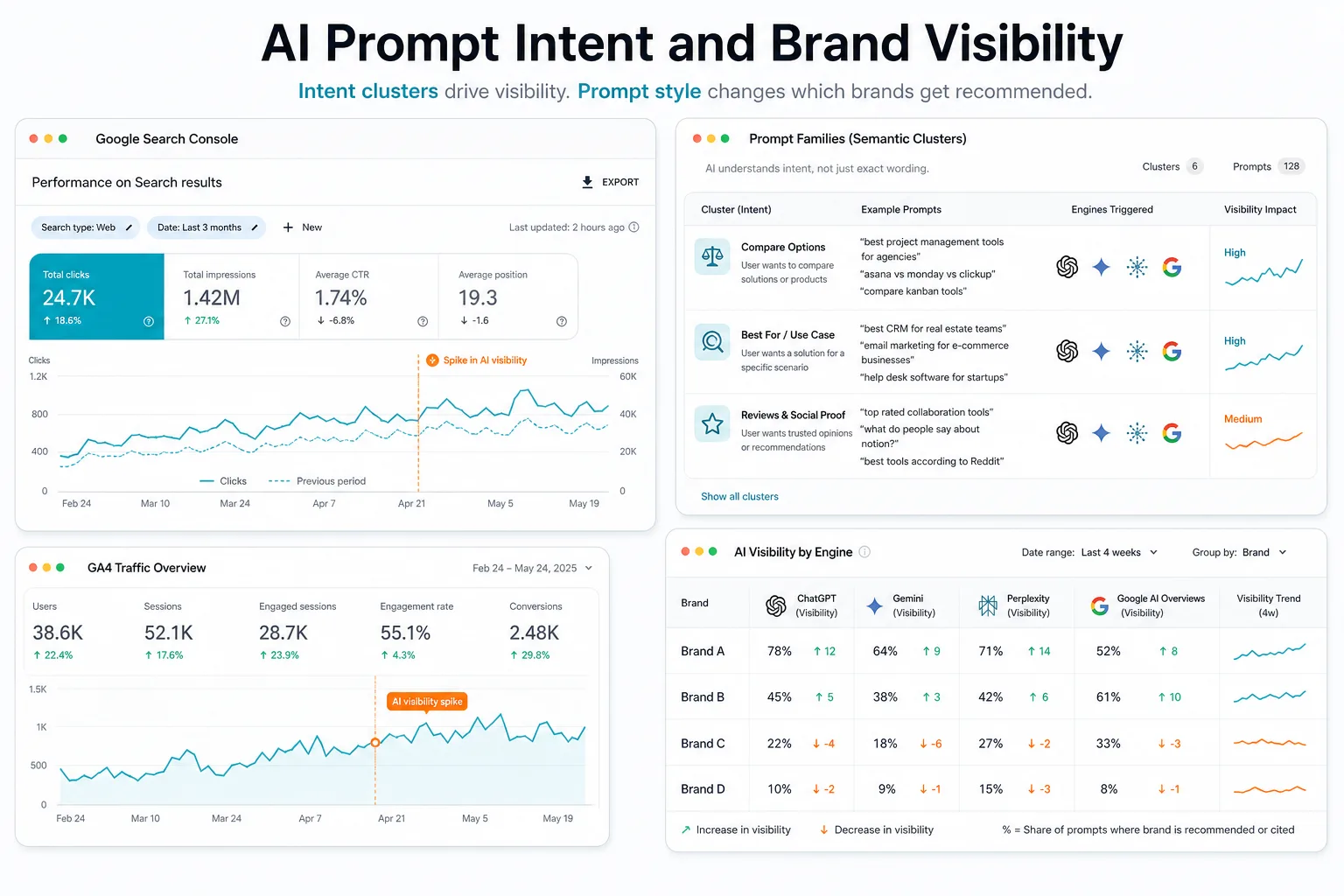
AI search is forcing marketers to rethink a familiar habit: chasing exact keywords. In multi-LLM environments, the question is rarely whether a brand matches one precise phrase. It is whether the system understands the intent behind the prompt and can map that intent to a useful recommendation.
That shift matters because human prompts look messy on the surface but often cluster tightly in meaning. Two users can ask for the same thing with very different wording and still trigger similar brand mentions. In practice, semantic search is doing more of the work than exact-match phrasing.
Key takeaway: for most AI visibility scenarios, the unit of analysis is not the keyword. It is the intent cluster, the funnel stage, and the prompt style that frames the task.
For marketers building an AI visibility program, this changes the measurement model. Instead of tracking every permutation, the smarter approach is to monitor representative prompt families, compare outputs across engines, and pay close attention to where wording actually changes recommendations.
Why prompt wording matters less than intent
Most of the time, prompt wording is a secondary signal. If two prompts express the same need, AI systems often return similar brand recommendations because they are interpreting meaning, not just scanning text. That is why phrases like “CRM software” and “customer relationship management tool” can lead to nearly identical outcomes.
This does not mean wording never matters. It means wording usually matters only when it changes the underlying task. A prompt that asks for a broad list of options, a comparison, or a recommendation can produce a different response shape than a prompt asking for a direct answer.
- Intent defines the problem the user wants solved.
- Prompt wording is the surface form of that problem.
- AI visibility depends on how the model interprets both.
This is why legacy keyword thinking can mislead teams in AI search. If your tracking model assumes that every phrase variation is a separate opportunity, you will overcount noise and undercount semantic coverage. A better model is to group prompts by meaning and then watch for shifts in brand mentions within each group.
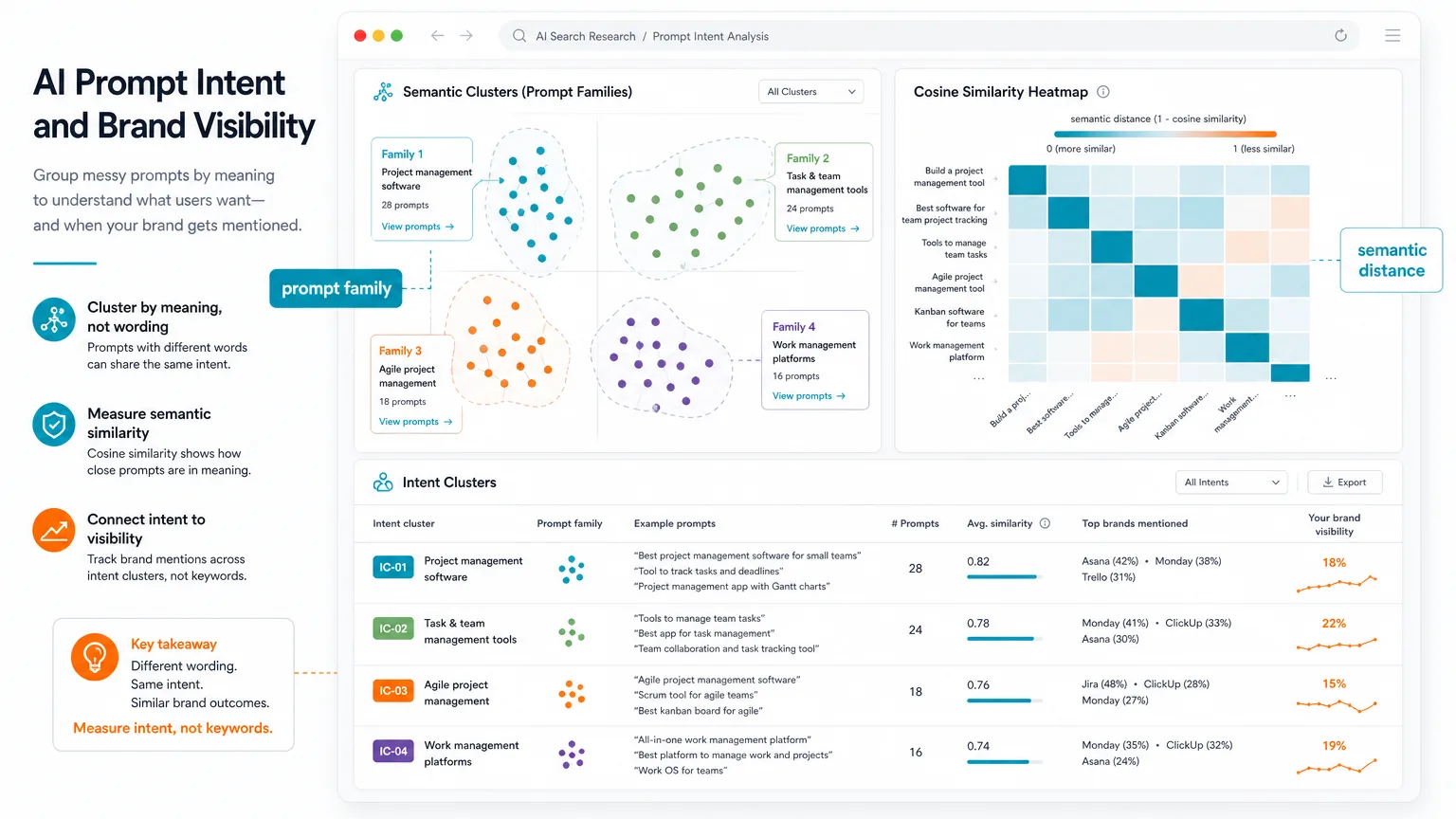
How the study measured prompt variation
The research behind this topic used a measurement approach that is much closer to how AI systems actually process language. Instead of comparing prompts by exact text overlap, it used semantic embeddings and cosine similarity to estimate how close two prompts are in meaning.
Cosine similarity is especially useful here because it expresses semantic distance on a scale from 0 to 1. A higher score means two prompts are more alike in meaning, even if the wording looks different. That matters because AI search systems are not simply matching terms; they are evaluating the intent space around a query.
Measurement principle: if you want to understand AI visibility, track meaning first and wording second.
The research design also matters. One part examined real human-written prompts, which showed how users naturally vary their phrasing. Another part generated controlled prompt variations in small semantic steps, which helped reveal where brand visibility starts to shift. Together, those two views create a more reliable picture than either one alone.
- Human prompts show real-world linguistic variation.
- Controlled prompts show threshold effects.
- Combined analysis shows where visibility stays stable and where it changes.
That is the right direction for AI search tracking. Marketers do not need to index every possible phrase. They need a semantic map of the prompts that matter most to their category, their funnel, and their competitive set.
What changed brand visibility
The most important finding is that brand visibility did not swing wildly with every wording tweak. In most cases, the same intent produced similar recommendations. What did change visibility was the combination of prompt style, funnel stage, and platform behavior.
One especially actionable result: concise keyword-style prompts and list-oriented prompts surfaced up to 20% more brands than open-ended prompts. That suggests the AI may interpret short, list-driven requests as broader comparison tasks, expanding the candidate set.
In other words, prompt style can act like a visibility lever. A user asking “best project management tools” may trigger a wider set of brand mentions than someone asking “what is the best project management tool for a small team and why?” The second prompt is more open-ended and evaluative, which can narrow or reshape the response.
- Short prompts often widen the brand set.
- List prompts can trigger comparison behavior.
- Open-ended prompts may produce fewer brands, but more context.
For marketers, this is a useful warning. If you only test one prompt style, you may misread your true AI visibility. The same brand can appear strongly in one query frame and disappear in another, not because the brand changed, but because the task framing changed.
Funnel-stage differences
The biggest volatility appears in the middle of the funnel. That is where users compare options, evaluate features, and narrow choices. These are the prompts most likely to shift brand recommendations when wording changes.
Top-of-funnel informational prompts tend to be more stable because the intent is broad and less brand-specific. Bottom-of-funnel transactional prompts are also relatively stable because the user’s goal is explicit. Middle-of-funnel prompts are the battleground because the system must infer which brands belong in the consideration set.
Practical implication: if you are prioritizing AI visibility work, start with comparison queries, not just informational or purchase-intent queries.
This is where many teams should rethink their monitoring. A brand may look healthy on broad informational prompts and still lose share in the comparison stage where decisions are actually made. That is why middle-of-funnel prompts deserve their own tracking bucket in any serious measurement playbook.
Differences across answer engines
One of the clearest strategic lessons is that answer engines do not behave identically. ChatGPT, Gemini, Perplexity, Google AI Mode, and Google AI Overviews may all interpret the same prompt set differently. That means visibility is not a single metric; it is a platform-specific outcome.
A brand can appear prominently in one engine and be absent in another, even when the prompt intent is stable. This is exactly why multi-engine monitoring matters. If you only track one system, you may mistake platform bias for market share.
- ChatGPT may favor certain recommendation patterns.
- Gemini may respond differently to list-style discovery prompts.
- Perplexity often behaves more like a research assistant.
- Google AI Overviews and AI Mode can reflect search-adjacent behavior with different thresholds.
That is also why AI visibility work should not be treated as a single content optimization task. It is a measurement science problem. Teams need platform-specific baselines, prompt families, and recurring checks that reveal whether a brand is consistently present across engines or only visible in one environment.
If your team is building a broader AI search strategy, it can help to connect this work with a structured framework like Generative Engine Optimization (GEO): Get Cited in ChatGPT, Gemini, Perplexity, and AI Overviews and Answer Engine Optimization (AEO): How to Win Featured Snippets, AI Answers, and Voice Search.
Practical tracking framework for marketers
A useful AI visibility program should be built around semantic prompt coverage, not keyword exhaustion. The goal is to monitor the prompt families that matter most to your category and understand how brand mentions change across intent, stage, and platform.
Here is a practical framework teams can use:
- 1. Build intent clusters. Group prompts by meaning, not by exact wording.
- 2. Separate by funnel stage. Track informational, comparison, and transactional prompts independently.
- 3. Test prompt styles. Compare open-ended questions, short keyword prompts, and list-oriented prompts.
- 4. Track multiple engines. Measure visibility in ChatGPT, Gemini, Perplexity, Google AI Mode, and Google AI Overviews.
- 5. Watch for threshold effects. Note when small wording shifts change brand recommendations.
For reporting, avoid a simple “present or absent” view. Instead, track:
- Brand mention frequency across prompt families
- Share of visibility within each intent cluster
- Engine-by-engine variance
- Prompt-style sensitivity
- Middle-of-funnel volatility
That structure gives you a much clearer picture of where AI recommendations are stable and where they are fragile. It also helps content, SEO, and product marketing teams align around the same question: which semantic scenarios should our brand own?
For agencies and in-house teams managing this at scale, the operational workflow should look familiar: use Search Console and analytics to understand demand, use rank tracking to watch traditional search movement, and layer AI visibility checks on top so you can see how semantic prompts are affecting brand discovery. If local intent is part of the mix, a location-specific page such as Professional SEO Services in Lahore | #1 SEO Agency can serve as a useful example of how service positioning intersects with AI recommendations.
Bottom line: optimize for the meaning space your buyers inhabit, then measure how different engines surface your brand inside that space.
The teams that win in AI search will not be the ones obsessing over every micro-variation. They will be the ones building durable coverage across intent clusters, especially in middle-of-funnel comparison moments where recommendations are most likely to change.
That is the strategic shift: from keyword paranoia to semantic control, from isolated prompts to prompt families, and from single-engine snapshots to a real measurement system.